Building a digital product today demands rock-solid reliability. An Advanced SaaS Platform Development Framework for Distributed, High‑Availability Applications tells users that their data, workflows, and trust remain safe. High availability isn’t technical jargon; it’s your service’s emotional foundation. Platform stutters during peak hours don’t just lose bandwidth; they erode reputation.
True excellence lives in invisible engineering: clusters failing over silently, databases syncing across continents in milliseconds, load balancers adapting to traffic surges. This guide maps building systems that thrive under global demand.
Before architecting, align technology with the business vision. Our product strategy framework for PE firms de-risks innovation.
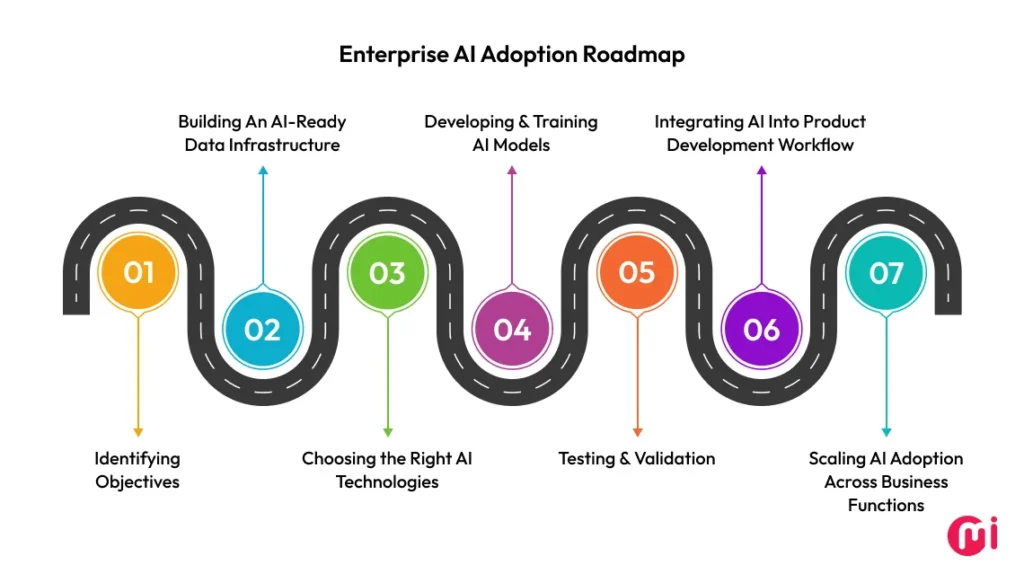
The Blueprint: High Availability through Redundancy
Advanced SaaS demands “N+1” redundancy, one extra resource beyond peak needs. Application servers, database replicas, and cache layers all maintain instant failover capability.
Distribute across availability zones, not single clouds. Geographic isolation protects against regional outages. This separates services stumbling during storms from platforms serving globally uninterrupted.
Table 1: Distributed Architecture Strategy Comparison
| Strategy Component | Vertical Scaling (Monolithic) | Distributed Framework (High Availability) |
| Failure Response | System-wide outage if the server fails | Traffic reroutes to healthy nodes instantly |
| Scaling Method | Add CPU/RAM to a single machine | Add instances across regions |
| Data Integrity | Single source of truth (easy) | Eventual consistency via replication |
| Maintenance | Requires scheduled downtime | Rolling updates with zero downtime |
| Ideal For | Early MVPs or internal tools | Global SaaS with 99.9% uptime needs |
Orchestration and Stateless Design
Distributed frameworks demand stateless applications. No server retains user session memory; data lives in distributed caches like Redis or global databases.
This enables infinite elasticity. Traffic surges? Spin up 50 instances in seconds. Stateless design means any server handles any request immediately.
Our SaaS platform development for subscription products leverages this for seamless scaling.
Solving Distributed Data Consistency
CAP theorem forces choices between Consistency, Availability, and Partition Tolerance. High-availability SaaS prioritizes “Eventual Consistency” for speed.
Database sharding splits massive datasets into parallel shards. Multi-master replication ensures data accessibility.
The 2026 SaaS Resiliency Stack
Table 2: The 2026 Resiliency Checklist for SaaS
| Reliability Layer | Required Action Item | Expected Outcome |
| Infrastructure | Multi-Region Deployment | Protection against major cloud outages |
| Database | Automated Failover Replicas | Instant data recovery during primary failure |
| Network | Anycast Load Balancing | Reduced latency via edge routing |
| Application | Circuit Breaker Patterns | Prevents cascading failures |
| Security | Zero-Trust Auth | Every microservice call is verified |
Zero Trust Security Model
Distributed systems expand attack surfaces. Zero Trust never assumes network safety—every microservice interaction demands authentication.
End-to-end encryption protects data at rest and in transit. Secure coding standards principles extend to SaaS backends.
Observability Beyond Monitoring
Single-server monitoring proves simple. Thousand-node clusters demand full observability: logs + metrics + traces.
Distributed tracing follows single requests across microservices. Slow login? Identify the exact bottleneck service. Proactive maintenance prevents outages.
The Human and Economic Cost of System Instability
While we often discuss an Advanced SaaS Platform Development Framework for Distributed, High‑Availability Applications in terms of bits and bytes, the true cost of failure is measured in human frustration and lost revenue. When a platform goes dark, it isn’t just a server error; it’s a halted workflow for a manager in London or a lost sale for a merchant in Tokyo.
We’ve seen that even a 1% drop in availability can lead to a 10% churn rate as users lose confidence in the product’s reliability. By building with a distributed mindset, you aren’t just optimizing your cloud spend; you’re protecting the professional lives of the people who depend on your service every day. Our enterprise mobile app solutions prove that high availability translates directly to customer retention.
High availability is, at its heart, a customer success strategy that pays dividends in brand loyalty and long-term contract renewals.
Decentralization and the Rise of Edge Computing
The next frontier for any Advanced SaaS Platform Development Framework for Distributed, High‑Availability Applications is moving logic closer to users through edge computing. Instead of requests traveling globally to central data centers, processing happens at local “edge nodes” just miles from devices.
This latency reduction makes SaaS feel instantaneous worldwide. Decentralizing application intelligence creates systems faster and more resilient to internet backbone outages. Our ecommerce mobile app development leverages edge strategies for global performance.
We’re moving toward a future where “cloud” becomes thousands of synchronized edge nodes delivering seamless digital experiences.
FAQs
What are “five nines” in SaaS development?
99.999% uptime equals ~5 minutes annual downtime. Requires redundant, distributed architecture with automatic failure recovery.
How does database sharding improve performance?
Splits large databases into parallel shards, reducing single-server load and enabling simultaneous query processing.
What defines stateless architecture?
Servers don’t retain user data between requests. Any instance handles any request, enabling effortless horizontal scaling.
Why choose observability over traditional monitoring?
Observability reveals why systems fail through distributed traces. Traditional monitoring only confirms if failure occurs.
What is a circuit breaker pattern in distributed systems?
A circuit breaker is a software design pattern used to detect failures and encapsulate the logic of preventing a failure from constantly recurring during maintenance or temporary external outages.
Build Platforms That Never Fail!
Investing in an Advanced SaaS Platform Development Framework means graduating from “hope it works” to “engineered for millions.”
At Pixact Technologies, we architect unbreakable infrastructure. From enterprise solutions to high-growth startups, our distributed systems expertise delivers 99.999% uptime you can trust.